Project → v1.2 [week 9]
Overview: move code towards v2.0 in small steps, start documenting design/implementation details in DG
v1.2 Summary of Milestone
| Milestone | Minimum acceptable performance to consider as 'reached' |
|---|---|
| Contributed code to the product as described in mid-v1.2 progress guide | some code merged |
| Described implementation details in the Developer Guide | some text and some diagrams added to the developer guide (at least in a PR), comprising at least one page worth of content |
| v1.2 managed using GitHub features (issue tracker, milestones, etc.) | A new version git tagged v1.2 is in your repo.There is evidence of an attempt (even if not completely successful) to use GitHub features as described in |
Project Schedule Tracking
In general, use the issue tracker (Milestones, Issues, PRs, Tags, Releases, and Labels) for assigning, scheduling, and tracking all noteworthy project tasks, including user stories. Update the issue tracker regularly to reflect the current status of the project. You can also use GitHub's new Projects feature to manage the project, but keep it linked to the issue tracker as much as you can.
Using Issues:
-
Record each of the user stories you plan to deliver as an issue in the issue tracker. e.g.
Title: As a user I can add a deadline
Description: ... so that I can keep track of my deadlines -
Assign the
type.*andpriority.*labels to those issues. -
When you start implementing a story, break it down to tasks. Define reasonable sized, standalone tasks. A task should be able to done by one person, in a few hours. e.g.
- 👍 Good: Update class diagram in the project manual for v1.4
- 👎 Bad (reasons: not a one-person task, not small enough): Write the project manual
-
Write a descriptive title for the issue. e.g. Add support for the 'undo' command to the parser.
-
There is no need to break things into VERY small tasks. Keep them as big as possible, but they should be no bigger than what you are going to assign a single person to do within a week. eg.,
Implementing parser: too big because it cannot be done by a single person in a week.Implementing parser support for adding of floating tasks: appropriate size.
-
Do not track things taken for granted. e.g.,
push code to reposhould not be a task to track. In the example given under the previous point, it is taken for granted that the owner will also (a) test the code and (b) push to the repo when it is ready. Those two need not be tracked as separate tasks. -
Omit redundant details. In some cases, the summary/title is enough to describe the task. In that case, no need to repeat it in the description. There is no need for well-crafted and detailed descriptions for tasks. A minimal description is enough. Similarly, labels such as
prioritycan be omitted if you think they don't help you. -
Assign tasks to team members using the
assigneesfield. At any point, there should be some ongoing tasks and some pending tasks against each team member. -
Optionally, you can use
status.ongoinglabel to indicate issues currently ongoing.
Using Milestones:
-
Use GitHub milestones to indicate which issues are to be handled for which milestone by assigning issues to suitable milestones.
-
Set the deadlines for milestones (in GitHub). Your internal milestones can be set earlier than the deadlines we have set, to give you a buffer.
-
Note that you can change the milestone plan along the way as necessary.
Wrapping up a Milestone:
Here are the conditions to satisfy for a milestone to be considered properly wrapped up:
-
A working product tagged with the correct tag (e.g. v1.2) is pushed to the main repo.
-
All tests passing on Travis for the version tagged above.
-
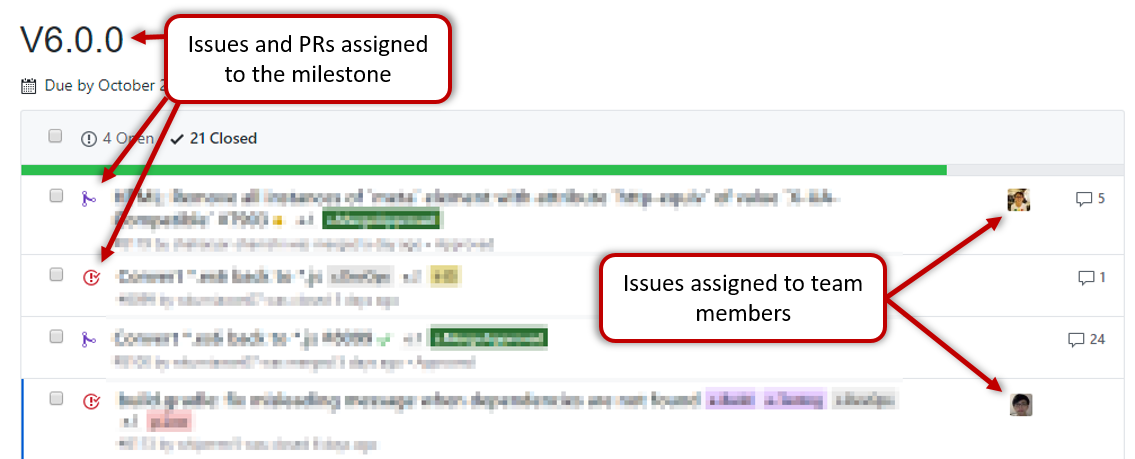
Milestone updated to match the product i.e. all issues completed and PRs merged for the milestone should be assigned to the milestone.
-
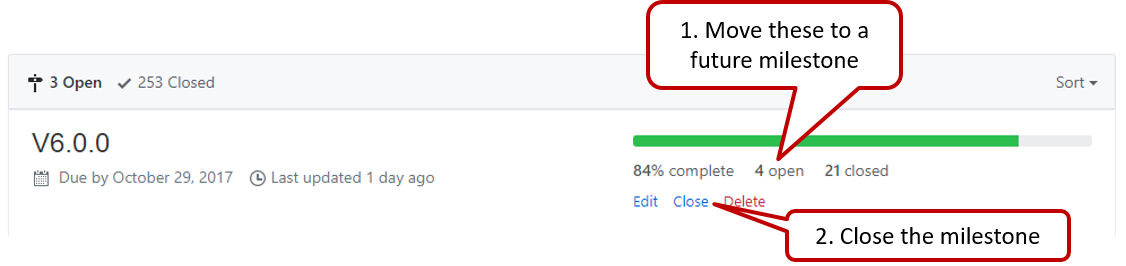
Milestone closed. If there are incomplete issues or unmerged PRs in the milestone, move them to a future milestone.
-
Optionally, issues for the next milestone are assigned to team members (this is not compulsory to do before the tutorial, but we recommend you to do it soon after the tutorial).
-
Optionally, future milestones are revised based on what you experienced in the current milestone e.g. if you could not finish all issues assigned to the current milestone, it is a sign that you overestimated how much you can do in a week, which means you might want to reduce the issues assigned to future milestones to match that observation.
-
Doing a 'release' on GitHub is optional for v1.1 and v1.2 but compulsory from v1.3.
v1.2 Project Management
- Manage, and close, the v1.2 milestone using GitHub.
v1.2 Product
- Merge some code into master (in the team repo).
💡 We use a tool called Collate to extract out code written by each member in your final project submission. The tool requires you to annotate code with special tags to mark code written by you. Adding those annotations is usually done at v1.3 but you are welcome to start early.
Steps to use Collate:
- Download
Collate-TUI.jarfrom the Collate Tool project - Annotate your code to indicate who wrote which part of the code (instructions given below)
- Run the Collate tool to collate code written by each person into separate files (instructions given below)
Annotating code to indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should appear only at the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments as only the content below that tag will be collated.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code but not documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement%%.- If an enhancement required you to do tiny changes in many places, there is no need to collate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the length of your collated files using dubious means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication.
Individual members are responsible for making sure their own collated files contain the correct content.
If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know. -
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
For code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These can be left out of collated code but can be mentioned in the Project Portfolio page if you want to claim credit for them.
Collating the annotated code
You need to put the collated code in the following folders
| Code Type | Folder |
|---|---|
| functional code | collated/functional |
| test code | collated/test |
| unused code | collated/unused |
Refer to Collate Tool's user guide to find how to run the tool over the annotated code.
Given below are DOS sample commands you can put in a batch file and run it to collate the code.
java -jar Collate-TUI.jar collate from src/main to collated/functional include java, fxml, css
java -jar Collate-TUI.jar collate from src/test to collated/test include java
java -jar Collate-TUI.jar collate from unused to collated/unused include java, fxml, css
The output should be something like the structure given below.
collated/
functional/
johndoe.md
sarahkhoo.md
ravikumar.md
ravikumarreused.md
test/
johndoe.md
sarahkhoo.md
ravikumar.md
unused/
johndoe.md
-
After running the collate tool, you are recommended to look through the generated .md files to ensure all your code has been extracted correctly.
-
Push the *.md files created to a folder called /collated in your repo.
v1.2 Documentation
-
User Guide: Update as necessary.
- If a feature has been released in this version, remove the
Coming in v2.0annotation from that feature. Also replace UI mock-ups with actual screenshots. - If a feature design has changed, update the descriptions accordingly.
- If a feature has been released in this version, remove the
-
Developer Guide:
- Each member should describe the implementation of at least one enhancement she has added (or planning to add).
Expected length: 1+ page per person - The description can contain things such as,
- How the feature is implemented.
- Why it is implemented that way.
- Alternatives considered.
- The stated objective is to explain the implementation to a future developer, but a hidden objective is to show evidence that you can document deeply-technical content using prose, examples, diagrams, code snippets, etc. appropriately. To that end, you may also describe features that you plan to implement in the future, even beyond v1.4 (hypothetically).
- For an example, see the description of the undo/redo feature implementation in the AddressBook-Level4 developer guide.
- Each member should describe the implementation of at least one enhancement she has added (or planning to add).
v1.2 Demo
Do an informal demo of the new feature during the tutorial. Each team member should demo their own work, using commit tagged as v1.2 in the master branch i.e. only features included in the current release should be demoed.